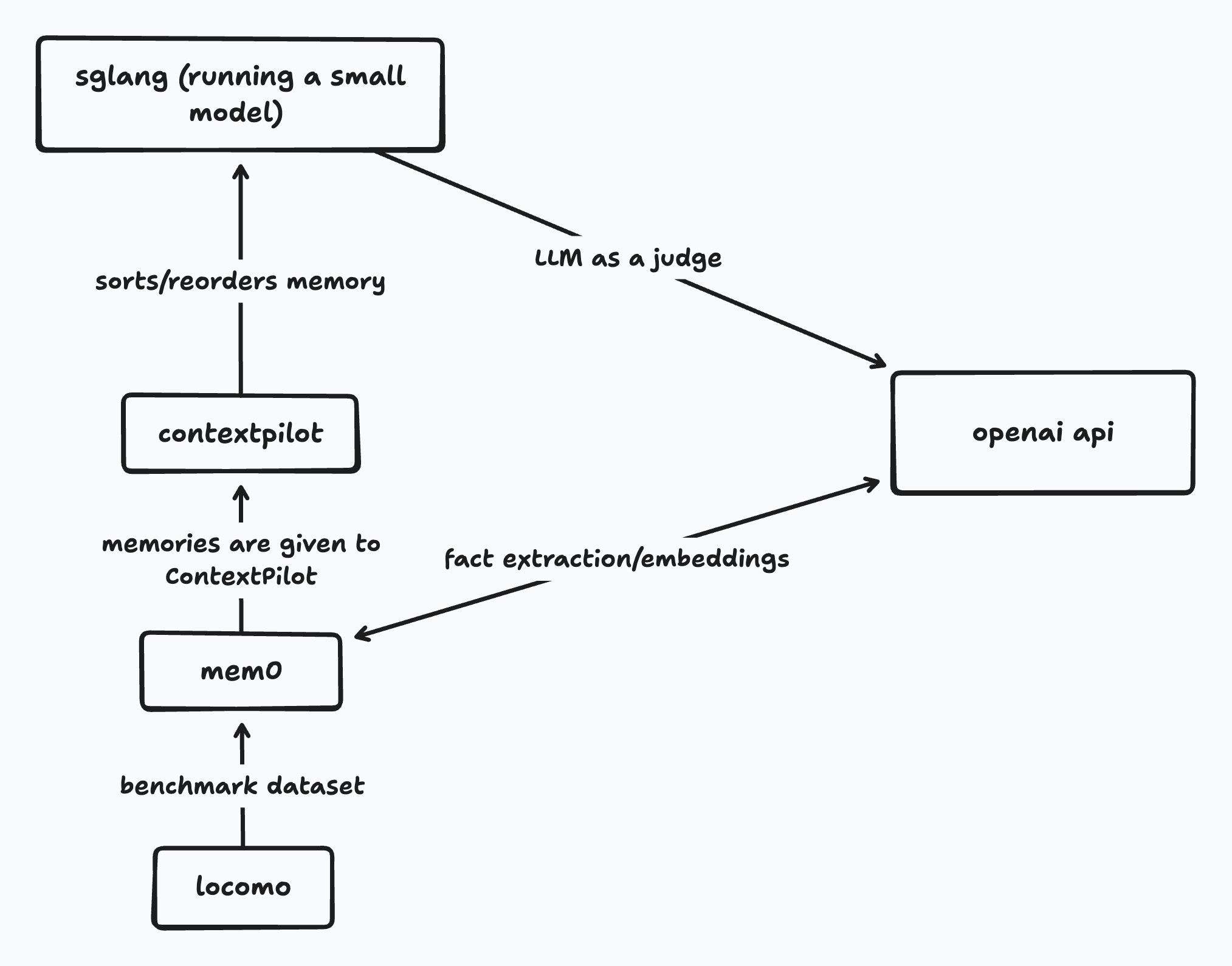
mem0 + ContextPilot LoCoMo Benchmark
This example measures TTFT and answer accuracy (token-F1, LLM judge) with and without ContextPilot context reordering, using mem0 as the memory backend and an OpenAI-compatible inference engine (SGLang or vLLM).
- Mem0 is an intelligent memory layer that facilitates memory storage and retrieval for agents.
- Locomo is a long conversation benchmark used to test memory retrieval.
Setup
pip install mem0ai openai tqdm
# Install your inference engine:
# SGLang:
pip install "sglang>=0.5"
# or vLLM:
pip install vllm
Start servers
python -m contextpilot.server.http_server --port 8765
In a separate terminal, start your inference engine:
export CONTEXTPILOT_INDEX_URL=http://localhost:8765
# SGLang:
python -m sglang.launch_server --model <model> --port 30000
# or vLLM:
python -m vllm.entrypoints.openai.api_server --model <model> --port 30000 --enable-prefix-caching
Run
export OPENAI_API_KEY=<your API key>
python examples/mem0_locomo_example.py
Environment variables
| Variable | Default | Description |
|---|---|---|
INFERENCE_URL | http://localhost:30000 | Inference engine endpoint (also accepts SGLANG_URL for backwards compatibility) |
CONTEXTPILOT_URL | http://localhost:8765 | ContextPilot server endpoint |
JUDGE_MODEL | gpt-4.1-2025-04-14 | OpenAI model for LLM judge |
LOCOMO_CONV_INDEX | 0 | Which LoCoMo conversation to use |
LOCOMO_MAX_QA | 150 | Max QA pairs to evaluate |
LOCOMO_MAX_TOKENS | 32 | Max generation tokens |
LOCOMO_NUM_TURNS | 150 | Multi-turn conversation length |
LOCOMO_TOP_K_LIST | 20,100 | Comma-separated top-k values to benchmark |
Results
LoCoMo conv 0, 102 memories, 150 turns:
| k | mode | ttft | judge |
|---|---|---|---|
| 20 | baseline | 0.0377s | 0.440 |
| 20 | reorder | 0.0315s | 0.460 |
| 100 | baseline | 0.1012s | 0.437 |
| 100 | reorder | 0.0554s | 0.420 |
General usage
Store and retrieve memories
from contextpilot.retriever import Mem0Retriever
retriever = Mem0Retriever(config={
"llm": {"provider": "openai", "config": {"model": "gpt-4.1-mini-2025-04-14"}},
"embedder": {"provider": "openai", "config": {"model": "text-embedding-3-small"}},
})
retriever.add_memory(
[{"role": "user", "content": "I'm allergic to peanuts"},
{"role": "assistant", "content": "Noted."}],
user_id="user123",
)
results = retriever.search_queries(
query_data=[{"text": "dietary restrictions?"}],
user_id="user123", top_k=20,
)
corpus_map = retriever.get_corpus_map()
Reorder with the library
import contextpilot as cp
contexts = [r["top_k_doc_id"] for r in results]
engine = cp.ContextPilot(use_gpu=False)
reordered, order = engine.reorder(contexts)
Reorder via the server (enables KV-cache tracking)
import requests
requests.post("http://localhost:8765/reset")
resp = requests.post("http://localhost:8765/reorder", json={
"contexts": contexts,
"use_gpu": False,
"linkage_method": "average",
"alpha": 0.001,
}).json()
reordered = resp["reordered_contexts"] # reordered doc ID lists
Multi-turn
Just call /reorder each turn — ContextPilot auto-detects whether the index exists and extends it incrementally:
for turn, query in enumerate(queries):
results = retriever.search_queries(
query_data=[{"text": query}], user_id="user123", top_k=20)
resp = requests.post("http://localhost:8765/reorder", json={
"contexts": [results[0]["top_k_doc_id"]],
"use_gpu": False,
"linkage_method": "average",
"alpha": 0.0005,
}).json()
reordered_ids = resp["reordered_contexts"][0]